Contextualized Topic Modeling with Python (EACL2021)
Combining BERT and friends with Neural Variational Topic Models

In this blog post, I discuss our latest published paper on topic modeling:
Bianchi, F., Terragni, S., Hovy, D., Nozza, D., & Fersini, E. (2021). Cross-lingual Contextualized Topic Models with Zero-shot Learning. European Chapter of the Association for Computational Linguistics (EACL). https://arxiv.org/pdf/2004.07737/
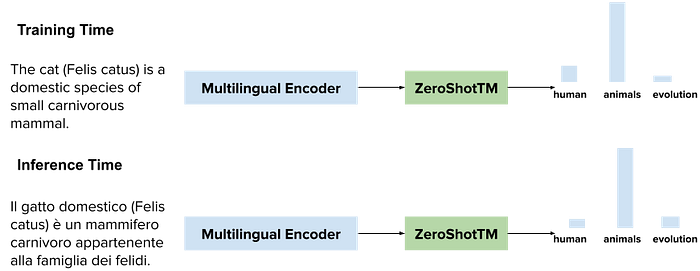
Suppose we have a small set of documents in Portuguese that is not large enough to reliably run standard topic modeling algorithms. However, we have enough English documents in the same domain. With our cross-lingual zero-shot topic model (ZeroShotTM), we can first learn topics on English and then predict topics for Portuguese documents (as long as we use pre-trained representations that account for both English and Portuguese).
We also release a Python package that can be used to run topic modeling! Take a look at our github page and at our colab tutorial!

Warm-Up: What is Topic Modeling?
Topic models allow us to extract meaningful patterns from text, making it easier to glance over textual data and better understand the latent distributions of topics that live underneath. Say you want to get a bird’s eye view on a set of documents you have at hand; well it is not a great idea to read them one by one, right?
Topic models can help: they look at your document collection and they extract recurrent themes.

Some Details
Topic models usually make two main assumptions.
First of all, a document can talk about different topics in different proportions. For example, imagine that we have three topics, i.e. “human being”, “evolution” and “diseases”. A document can talk a little about humans, a little about evolution, and the remaining about animals. In probabilistic terms, we can say that it talks 20% about humans, 20% about evolution, and 60% about animals. This can be easily expressed by a multinomial distribution over the topics. This probability distribution is called document-topic distribution.

Secondly, a topic in topic modeling is not an unordered list of words: in a topic like “animal, cat, dog, puppy, ” each word of the vocabulary contributes with a specific weight. In other words, also a topic can be expressed by a multinomial distribution, where the words of the vocabulary with the highest probability are the ones that contribute the most to the given topic. This distribution is called word-topic distribution.
The most well-known topic model is LDA (Blei et al., 2003) that also assumes that words in a document are independent of each other, i.e. are expressed as Bag Of Words (BoW). Several topic models have been proposed across the years, addressing a wide variety of problems and tasks. State-of-the-art topic models include neural topic models based on variational autoencoders (VAE) (Kingma & Welling, 2014).
Two Problems with Standard Topic Modeling
However, this kind of models usually have to deal with two limitations:
- Once trained, most topic models cannot deal with unseen words, this is because they are based on Bag of Words (BoW) representations, which cannot account for missing terms.
- It is difficult to apply topic models to multilingual corpora without combining the vocabulary of multiple languages (Minmo et al, 2009; Jagarlamudi et al, 2010), making the task computationally expensive and without any support for zero-shot learning.
How do we solve this?
Contextualized Topic Model: inviting BERT and friends to the table
Our new neural topic model, ZeroShotTM, takes care of both problems we just illustrated. ZeroShotTM is a neural variational topic model that is based on recent advances in language pre-training (for example, contextualized word embedding models such as BERT).
Yes, you got it right! We propose to combine deep learning based topic models with recent embeddings techniques such as BERT or XLM.

A pre-trained representation of the documents is passed to the neural architecture and then used to reconstruct the original BoW of the document. Once the model is trained, ZeroShotTM can generate the representations of the test documents, thus predicting their topic distributions even if the documents contain unseen words during training.
Moreover, if we use a multilingual pre-trained representation during training, we can get a significant advantage at test time. Using representations that share the same embedding space allows the model to learn topic representations that are shared by documents in different languages. A trained model can then predict the topics of documents in unseen languages during training.
We extend a neural topic model, ProdLDA (Srivastava & Sutton, 2017), that is based on a Variational Autoencoder. ProdLDA takes as input the BoW representation of a document and learns two parameters μ and σ² of a Gaussian distribution. A continuous latent representation is sampled from these parameters and then passed through a softplus, thus obtaining the document-topic distribution of the document. Then, this topic-document representation is used to reconstruct the original document BOW representation.
Instead of using the BoW representation of documents as model input, we pass the pre-trained document representation to the neural architecture and then use it to reconstruct the original BoW of the document. Once the model is trained, ZeroShotTM can generate the representations of the test documents, thus predicting their topic distributions even if the documents contain unseen words during training.
TL;DR
ZeroShotTM has two main advantages: 1) it can handle missing words in the test set and 2) inherits the multilingual capabilities of recent pre-trained multilingual models.
With standard topic models, you often have to remove from the data those words you have in the test set but that are missing in the training set. In this case, since we rely on a contextualized model, we can use it to build the document representation of the test document expressing the full power of these embeddings. Moreover, standard multilingual topic modeling requires to take care of multiple language vocabularies.
ZeroShotTM can be trained on English data (that is a data-rich language) and tested on more low resource data. For example, you can train it on English Wikipedia documents and test it on completely unseen Portuguese documents, as we show in the paper.
Contextualized Topic Modeling: A Python Package
We have built an entire package around this model. You can run the topic models and get results with a few lines of code. On the package homepage, we have different Colab Notebooks that can help you run experiments.
You can follow the example here or directly on colab.
Depending on the use case, you might want to use a specific contextualized model. In this case, we are going to use the distiluse-base-multilingual-cased model.
When using topic models, it is always better to perform text pre-processing, but when we are dealing with contextualized models, such as BERT or the Universal Sentence Encoder it might be better not to do much pre-processing (as these models are contextual and use the context a lot).
Today’s Task
We are going to train a topic model on English Wikipedia documents and predict the topics for Italian documents.
The first thing you need to do is to install the package, from the command line you can run:
Be sure to install the correct PyTorch version for your system and also, if you want to use CUDA, install the version that supports CUDA (you might find it easier to use colab).
Data
Let’s download some data, we are going to get them from an online repository. These two commands will download the English abstracts and the Italian documents.
If you open the English file, the first document you see should contain the following text:
The Mid-Peninsula Highway is a proposed freeway across the Niagara Peninsula in the Canadian province of Ontario. Although plans for a highway connecting Hamilton to Fort Erie south of the Niagara
Escarpment have surfaced for decades,it was not until The Niagara...Now, let’s apply some preprocessing. We need this step to create the bag of words that is going to be used by our model to represent the topics; Nevertheless, we will still use the non pre-processed dataset to generate the representations from distiluse-base-multilingual-cased model.
Let’s Train Folks
Our pre-processed documents will contain only the 2K most frequent words, this is an optimization step that allows us to remove words that might not be too meaningful. The TopicModelDataPreparation object allows us to create our dataset to train the topic model. Then with the use of our ZeroShotTM object, we can train the model.
Playing with the model
One thing we can quickly check is our topics. Running the following method should get you some topics in output
They are noice, ain’t they?
[['house', 'built', 'located', 'national', 'historic'],
['family', 'found', 'species', 'mm', 'moth'],
['district', 'village', 'km', 'county', 'west'],
['station', 'line', 'railway', 'river', 'near'],
['member', 'politician', 'party', 'general', 'political'],
...
...If you want to have a better visualization you can get it using this:

Yea, but where’s the multilingual?
So now, we need to do some inferences. We could nonetheless predict the topic from some new unseen English documents, but why don’t we try with Italian?
The procedure is similar to what we have already seen; in this case, we are going to collect the topic distributions for each document and extract the most probable topic for each document.
The document contained the following text, about a movie:
Bound - Torbido inganno (Bound) è un film del 1996 scritto e diretto da Lana e Lilly Wachowski. È il primo film diretto dalle sorelle Wachowski, prima del grande successo cinematografico e mediatico di Matrix, che avverrà quasi quattro anni dopoLook at the predicted topic:
['film', 'produced', 'released', 'series', 'directed', 'television', 'written', 'starring', 'game', 'album']Makes sense, right?
This ends this blog post, feel free to send me an email if you have questions or if you have something you’d like to discuss :) You can also find me on Twitter.
References
Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. JMLR.
Jagarlamudi, J., & Daumé, H. (2010). Extracting multilingual topics from unaligned comparable corpora. ECIR.
Kingma, D. P., & Welling, M. (2014). Auto-encoding variational bayes. ICLR.
Mimno, D., Wallach, H., Naradowsky, J., Smith, D. A., & McCallum, A. (2009, August). Polylingual topic models. EMNLP.
Srivastava, A., & Sutton, C. (2017). Autoencoding variational inference for topic models. ICLR.
Credits
The content of this blog post has been mainly written by me and by Silvia Terragni. Many thanks to Debora Nozza and Dirk Hovy for the comments on a previous version of this article.